不卡顿、免费的满血版DeepSeek-R1 API,在无问芯穹这里用上了,更有异构算力鼎力相助
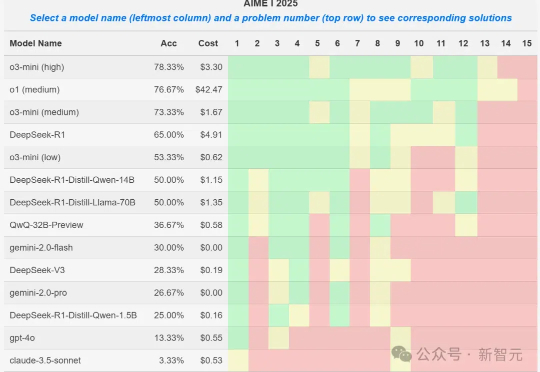
不卡顿、免费的满血版DeepSeek-R1 API,在无问芯穹这里用上了,更有异构算力鼎力相助还在为 DeepSeek R1 官网的卡顿抓狂?无问芯穹大模型服务平台现已上线满血版 DeepSeek-R1、V3,无需邀请即可免费用 Token!另有异构算力鼎力相助,支持通过 Infini-AI 异构云平台一键获取 DeepSeek 系列模型与多元异构自主算力服务。
来自主题: AI资讯
9858 点击 2025-02-11 14:56